

Avalonia nutzt XAML als Beschreibungssprache für UIs. XAML wurde mit WPF eingeführt und hat sich seitdem im .NET-Ökosystem gut verbreitet und etabliert. Die Grundidee von XAML ist denkbar einfach. Es nutzt XML als Basis, erweitert es aber an einigen Stellen mit zusätzlichen Features für die UI-Entwicklung. Ein gutes Beispiel solcher Features sind MarkupExtensions. Viele von uns (inkl. mir selbst) arbeiten gerne mit XAML, an einigen Stellen sorgt es aber für mehr Tipparbeit, als es sein müsste. Ein Beispiel dafür sind die teilweise vielen und langen Imports für XAML-Namespaces, die am root-Knoten geschrieben werden müssen. .NET MAUI adressiert dieses Problem im aktuellen Release [1], doch gibt es auch Wege in Avalonia? In diesem Artikel möchte ich einige Tricks zeigen, um speziell mit diesem Problem in Avalonia eleganter umzugehen.
Blog
Ein Überstunden-Konto für einen Solo-Selbstständigen

Ich bin Stand September 2025 etwas über 4 Jahre in der Selbstständigkeit als freier Software Engineer und Trainer. In dieser Zeit habe ich vieles ausprobiert, um mein Angebot weiter zu verbessern, mehrere Kundenbeziehungen aufzubauen und auch um eine gesunde Work-Life Balance einzuhalten. Letzteres ist in Bezug auf Selbstständigkeit ein schwieriger Begriff, arbeitet man doch als Selbstständiger i. d. R. mehr, als bei einer Anstellung üblich ist. Nichtsdestotrotz ist es mir wichtig, eine gewisse Balance zu halten. Vor ca. 2 Jahren, also im Jahr 2023, habe ich deswegen für mich ein Überstunden-Konto eingeführt. Wie ich das für mich als Solo-Selbstständiger definiert habe und was mir das in Bezug auf Work-Life Balance bringt, beschreibe ich in diesem Artikel.
ValueConverter in Avalonia – 3 Wege, sie in XAML einzubinden

Avalonia hat sich als modernes, Cross-Platform-UI‑Framework für .NET etabliert. Ein zentrales Element bei der Datenbindung ist dabei der ValueConverter: eine kleine Logikschicht, die Werte und Objekte zwischen ViewModel und UI umwandeln kann. In anderen auf XAML basierenden Frameworks wie WPF ist das Konzept bereits seit Jahrzehnten bekannt – in Avalonia funktioniert es grundsätzlich ähnlich und wird auch häufig genutzt. Für die Art, wie wir ValueConverter im XAML-Code einbinden, gibt es allerdings wie so oft mehrere verschiedene Wege. Diesen Artikel möchte ich nutzen, um einige davon zu zeigen. Leser können sich damit eine Meinung bilden, welche davon für sie selbst die sinnvollste ist.
Testautomatisierung mit Avalonia #2

Vor fast genau zwei Jahren habe ich bereits einen Artikel darüber geschrieben, wie Testautomatisierung auf Ebene der UI mit Avalonia möglich ist [1]. Der dort beschriebene Ansatz funktioniert, erfordert aber auch etwas Starthilfe in Form von einigen Utility-Klassen und der richtigen Konfiguration von Avalonia und Testframework. Hintergrund ist die Tatsache, dass Avalonia wie andere UI-Frameworks Single-Threaded ist und ähnlich wie WPF mit einem Application Objekt arbeitet. In automatisierten UI-Tests muss man sich somit darum kümmern, die Tests innerhalb des UI-Threads auszuführen, eine Instanz von Application zu teilen und die parallele Ausführung der Tests zu deaktivieren. Mit den Paketen Avalonia.Headless.XUnit oder Avalonia.Headless.NUnit sind diese Schritte aber glücklicherweise nicht mehr erforderlich. In diesem Artikel beschäftigen wir uns mit Avalonia.Headless.XUnit, da ich selber typischerweise mit XUnit arbeite.
Avalonia UI – Per MarkupExtension auf das Betriebssystem eingehen

Avalonia UI rendert alle Elemente selbst. Das hat insbesondere den Vorteil, dass die eigene Applikation und damit das eigene Corporate Branding auf jeder Plattform gleich aussieht. Es gibt noch einige andere Vorteile dieses Ansatzes. In diesem Artikel möchte ich aber darauf eingehen, wie man mit Stellen umgehen kann, an denen es Unterschiede zwischen den verschiedenen Betriebssystemen gibt. Es gibt i. d. R. nur Wenige, eines davon ist die Menüleiste. Für Windows und Linux wird sie typischerweise im Hauptfenster ganz oben angezeigt. Unter macOS ist das anders – dort stellt das Betriebssystem selbst eine Menüleiste am oberen Bildschirmrand bereit. Somit ist es unter macOS gar nicht notwendig, das Hauptmenü selbst zu zeichnen. Hier im Artikel beschreibe ich, wie ich das Thema bei GPXviewer 2 mittels einer MarkupExtension gelöst habe.
GPXviewer 2 – Mit Avalonia UI auf mehrere Plattformen
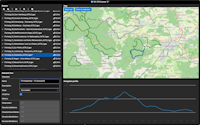
Es gibt eine lange Liste möglicher Frontend-Fameworks, zwischen denen .NET-Entwicklungsteams wählen können. Ein sehr spannender Kandidat ist Avalonia UI [1]. Ursprünglich als Cross-Plattform Alternative zu WPF gestartet, bietet es heute neben den bekannten Desktops von Windows, macOS und Linux auch Unterstützung für mobile Plattformen (Android, iOS), für den Browser (via WebAssembly) und als Alleinstellungsmerkmal auch für Embedded Linux. Für mein OpenSource Tool GPXviewer war für mich neben Windows insbesondere macOS relevant. Ganz einfach aus dem Grund, weil ich mittlerweile mehr Zeit auf meinem MacBook verbringe, als auf meinem Windows Laptop [2]. Daher habe ich mich entschieden, GPXviewer von WPF nach Avalonia UI zu portieren – daraus entstand dann das Projekt GPXviewer 2 [3]. In diesem und nachfolgenden Artikeln möchte ich einige Erfahrungen teilen, die ich damit sammeln durfte.
Request-Komprimierung mit C# und HttpClient

HTTP-Kommunikation ist Standard. Das gilt sowohl für den Browser, als auch für die allermeisten Services, die derzeit gebaut werden. Ebenfalls längst Standard ist die Komprimierung des Response – sofern der anfragende Client das auch unterstützt. Doch wie sieht es mit dem Request aus? Ich stoße in meinen Projekten gelegentlich auf Szenarien, bei denen es auch große Requests gibt, die schnell übertragen werden müssen. Insbesondere bei langsamen Übertragungswegen stößt man hier schnell auf Probleme. Request-Komprimierung kann an dieser Stelle für eine deutliche Steigerung der Performance sorgen. In C# gibt es im Standard beim HttpClient leider keinen Schalter, um eine Request-Komprimierung zu aktivieren. Man muss also selbst Hand anlegen. In diesem Post möchte ich einen eleganten Weg zeigen, um genau das zu erreichen.
Als .NET Entwickler auf dem MacBook Pro

Vor etwas über zwei Jahren startete ich für mich persönlich ein Experiment. Ich habe mir einen MacBook Pro mit dem zu der Zeit neuen M1 Prozessor gekauft. Für mich war das tatsächlich ein großer Schritt, da ich meinen Fokus auf der .NET Plattform von Microsoft habe und damit seit über 15 Jahren bis auf wenige Linux-Ausflüge primär auf Windows unterwegs war. Der neue M1 Prozessor und dessen Balance aus Leistung und Akkulaufzeit war dabei ein Auslöser der Entscheidung für das Experiment. Es kamen aber auch andere Faktoren dazu. Immer häufiger bin ich etwa bei Kunden und im Bekanntenkreis auf macOS Benutzer gestoßen. Die Zeit war also mehr als reif, mich selbst als Entwickler mit der Plattform zu beschäftigen. Über meine Erfahrungen, Ärgernisse und warum es für mich Stand heute eine gute Entscheidung war, erfährst du mehr in diesem Artikel.
Automatische Integrations- und Systemtests mit Testcontainers

Im letzten Artikel [1] haben wir uns mit automatischen Integrationstests mit ASP.NET Core beschäftigt. In diesem Artikel baue ich darauf auf und ergänze das Thema um eine sehr spannende Variante zum Mocking fremder Services. Die meisten Entwickler kennen das Problem. Sobald man auf der Integrations- oder Systemtestebene testen möchte, muss man sich über die Abhängigkeiten zu anderen Services Gedanken machen. Das fängt bereits bei der Datenbank an und hört dort leider nicht auf. Es geht i. d. R. auch um andere Services, die während des Testens benötigt werden. Zur Lösung des Problems gibt es grundsätzlich zwei Varianten: Man bindet externe Services während des Tests an oder man versteckt sie hinter einer Schnittstelle und baut einen Mock darum. Die erste Variante ist zwar realitätsnäher, hat aber einige gewichtige Nachteile. So ist die Laufzeit von Tests länger, man hängt vom Status eines externen Service ab und mehrere, konkurrierend laufende Tests können zum Problem werden. Mit Testcontainers können wir die meisten dieser Nachteile Streichen. Wie genau erkläre ich in diesem Artikel.
Automatische Integrationstests mit ASP.NET Core

Softwaretest ist ein Thema, was jeden Softwareentwickler stets begleitet. Wenn es um Testautomatisierung geht, erhalten wir dazu ein breites Set an Werkzeugen in die Hand gedrückt. Das geht bei Testframeworks wie xUnit los und geht über die Integration solcher Frameworks in moderne IDEs wie Visual Studio und Rider weiter. In diesem Beitrag möchte ich mir eines dieser Werkzeuge herauspicken und ins Rampenlicht rücken: Es geht um Integrationstests mit ASP.NET Core. Warum? Genau diese Art von Tests hat einen sicheren Platz in meinem Werkzeugkoffer eingenommen. Es passt sehr gut zu der Art, wie ich Testautomatisierung und das Thema Testpyramide / Testdiamant schon seit sehr langer Zeit sehe (mehr dazu unter [1]). Ich setze bei Testautomatisierung i. d. R. mehr auf einen sog. „Testdiamanten“, als auf eine „Testpyramide“. Dafür gibt es viele Gründe. Ein wichtiger ist, dass damit das Verhalten einer Softwarekomponente auf einer höheren Ebene getestet und damit festgezogen wird. So viel möchte ich jetzt aber nicht über die Gründe schreiben, sondern jetzt zum Thema des Artikels kommen.