
Performance-Optimierung ist immer und überall ein Thema, welches viel Zeit und starke Nerven fordert. Zudem wird gerne an Stellen optimiert, welche für die Gesamtperformance letzten Endes nicht wirklich ausschlaggebend sind. Ich persönlich bin deswegen überwiegend der Meinung, während der Entwicklung selbst weniger auf Performance zu schauen und sich von Optimierungen nicht unnötig aufhalten zu lassen. Dort wo es hackt, kann im Nachhinein nachgebessert werden. Im Prinzip bin ich genauso bei der Entwicklung von SeeingSharp (Arbeitstitel für 3D-Engine) vorgegangen. Das Grundgerüst ist zunächst so aufgebaut, dass es aktuelle Anforderungen daran gut abdecken kann. Für künftige Aufgaben bin ich gerade dabei, an der Einen oder anderen Stelle zu schrauben, um so die nötige Leistung aus dem System zu bekommen. Die Schritte dazu und erste Ergebnisse erkläre ich kurz in diesem Beitrag.
Vorgehen
Zunächst etwas Grundsätzliches: Wie gehe ich bei der Optimierung vor? Das erste und m. E. wichtigste ist es, an den wichtigsten Stellen Zeitmessungen einzubauen. Ohne ein Gefühl zu haben, wo etwas wie lange dauert, braucht man eben nicht tiefer einsteigen. Am Beispiel 3D-Engine ist das umso wichtiger, denn pro Bild sind viele (Teil-)Aufgaben zu erfüllen. So müssen neben dem tatsächlichen Rendering auch Aufgaben wie Clipping (Sichtbarkeits-Prüfung), Animation, Kollissionsprüfung, Ressourcen laden/entladen und Berechnung der Transformationen erfolgen. Optimierung auf Verdacht führt hier fast zwangsweise dazu, die falsche Stelle zu erwischen. Aus diesem Grund war es mein erster Arbeitsschritt, entsprechende Kennzahlen zu Berechnen und in einer Test-Oberfläche anzuzeigen. Bei den Kennzahlen handelt es sich im Prinzip nur um die Anzahl Millisekunden, welche gewisse Logik-Blöcke mit Mittel über eine Zeitspanne von ein paar Sekunden benötigt haben. Nachfolgender Screenshot zeigt ein entsprechendes Beispiel.
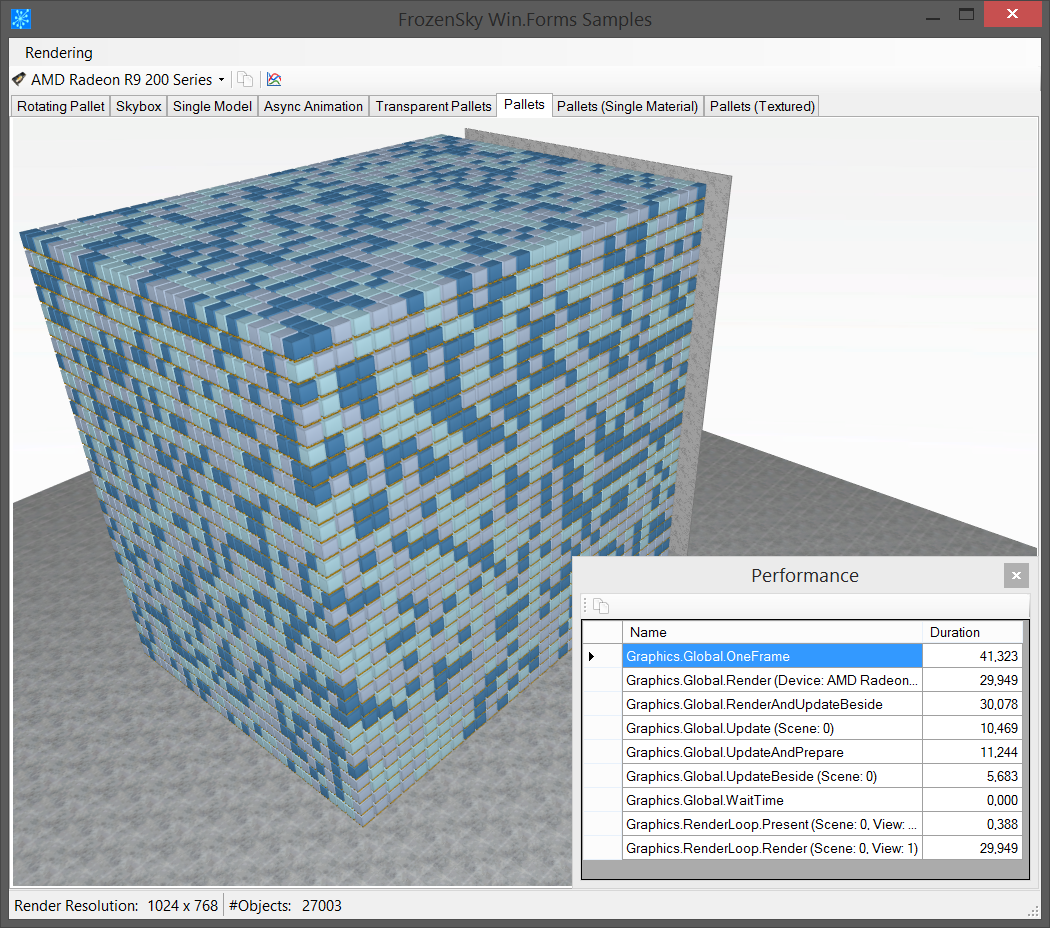
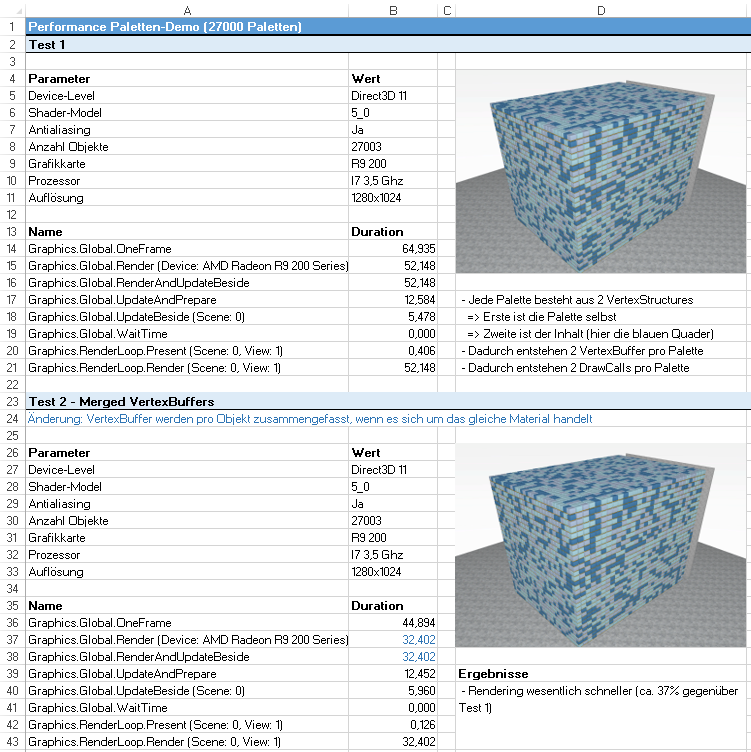
Die so generierten Kennzahlen kopiere ich anschließend in eine Excel-Datei und schreibe entsprechend die Voraussetzungen für den jeweiligen Test dazu. Voraussetzungen sind z. B. Themen wie die Auflösung, die gerenderte Szene, Anzahl Objekte, das verwendete Shader-Model und noch ein paar weitere. Zusätzlich kopiere ich auch einen Screenshot dazu, um später auch noch ein Bild davon zu haben, was überhaupt getestet wurde. Nachfolgend ein Beispiel-Screenshot von einer der dadurch entstandenen Excel-Dateien.
Erste Ergebnisse
Ein sehr interessanter Punkt ist der Einfluss des FeatureLevels. In Direct3D wird damit unterschieden, welche Features einer Hardware angesprochen werden können. So implementiert die Grafik-Hardware des ersten Surface-Tablets lediglich FeatureLevel 9_1 und hat damit entsprechend eingeschränkte Fähigkeiten. Am Desktop-PC dagegen hat meine Radeon-Grafikkarte das FeatureLevel 11_1, also im Prinzip das derzeit aktuellste. Ich persönlich war vorher immer der Meinung, dass das Rendering, sofern alle anderen Parameter gleich sind, sich bei den verschiedenen FeatureLeveln gleich verhält – es passiert schließlich letzten Endes das gleiche… oder sollte man zumindest meinen. Dem ist aber scheinbar nicht so, denn in meinen Tests war die gleiche Grafikkarte mehr als die Hälfte langsamer, wenn ich sie mit FeatureLevel 9_1 angesteuert habe als mit FeatureLevel 11. In Konsequenz habe ich SeeingSharp so angepasst, dass immer versucht wird, die Grafik-Hardware mit einem möglichst hohem FeatureLevel anzusprechen.
Ein anderer Punkt ist die Anzahl der VertexBuffer. Diese zu minimieren scheint grundsätzlich die Performance zu steigern. Hier muss ich zugeben, dass mein Ansatz, zunächst weniger auf Optimierung zu schauen, zu einer hohen Stückelung der Grafik-Ressourcen geführt hat. So entstehen unnötig viele VertexBuffer, Materialien und letzten Endes auch DrawCalls. Grundsätzlich ist das ein großer Nachteil, denn vor allem die Anzahl der DrawCalls kann einen spürbaren Einfluss auf die Performance haben. Ein erster relativ einfacher Schritt für mich war hier, die Anzahl der verwendeten VertexBuffer zu Minimieren. Letzten Endes bedeutet dass nur, einige vorher gesplittete Speicherblöcke nach Möglichkeit zu verbinden. Nach ein paar Stunden Arbeit konnte ich damit obige Paletten-Demo um 40% beschleunigen.
Weitere Schritte
Es bleibt natürlich noch viel zu tun. Performance ist ein Thema, welches bei der Entwicklung immer im Nacken sitzt. Letzten Endes bin ich aber froh, diesen Weg wie hier gewählt zu haben und erst im Nachhinein stärker zu optimieren. Einen Punkt nämlich will ich hier besonders herausstreichen: An welchen Stellen wirklich Performance verloren geht, ist i. d. R. auch erst im Nachhinein zu erkennen.